- Language(s)
- C++
- Framework(s)
- OpenMP
- Engine
- N/A
- Platform(s)
- Windows
- Could be ported to other platforms including Linux and MacOS
- Software
- Visual Studio
During my final year of study, I was tasked with optimising a CPU-based ray tracing program.
Prior to this I worked on optimising a program that calculated Pi using the Monte-Carlo algorithm. I made an attempt on the CPU using the standard thread library and an attempt on the GPU of my own making*.
I also implemented and optimised some prime number sieves - I did this using both OMP and the standard thread library.
From these two experiments I learned that it was best to do as few complex calculations as possible (square roots, random number generation, etc.) and that some calculations take longer than others.
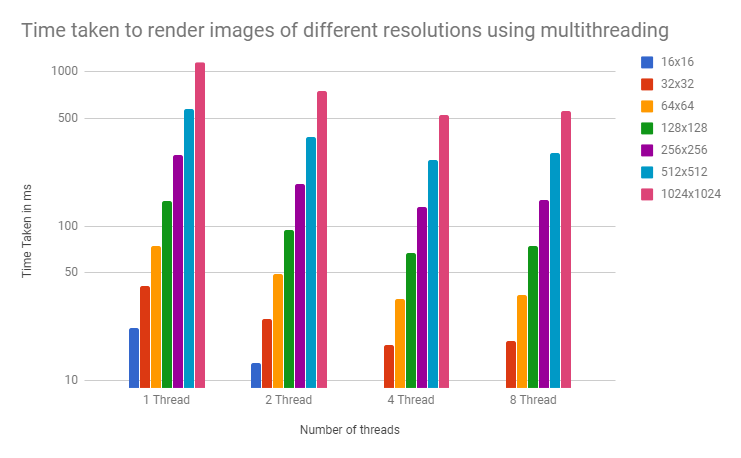
For my first attempt I split the image into 4 rows of equal size and rendered them all at the same time. Then, I decided to split the image up less evenly with one thread working on the top half and 3 others working on the more difficult spheres.
I thought that this would be faster since when I did the primes experiment it was more efficient to dedicate more threads to the harder tasks. It transpired that this was not the case for the ray-tracer.
Each portion of the image took around the same time to render. My last optimisation was to get it to use 8 threads instead of four.
I then tested the ray-tracer on different machines. Intriguingly, I found that it ran faster on a 4-core Intel CPU (an i7-4790k) than on an 8-core AMD CPU (an FX-8350). I determined that the reason for this was that even though the AMD had the same clock speed (4GHz), the Intel CPU had hyper-threading and that the AMD CPU only had 4-floating point units (it was advertised as having 8 cores because it had 8 integral units).
* I want to talk a little bit about my Pi calculations on the GPU because I find it interesting:
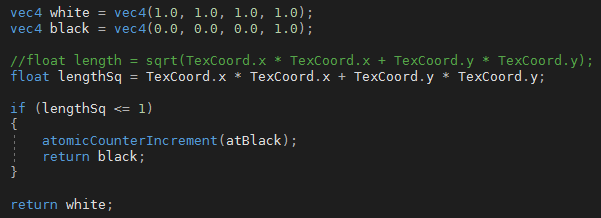
When doing the Monte-Carlo method you imagine a square, and a circle within that square (whose radius is the square's width). You then pick various random points and determine whether or not they fall within the circle. This is done by calculating the distance they are from the centre using their coordinates.
There are some optimisations you can do. You can use only a quarter of the circle then multiply the result (number in circle / number of iterations) by 4. You can set the radius to one so you don't have to do any square-rooting calculations.
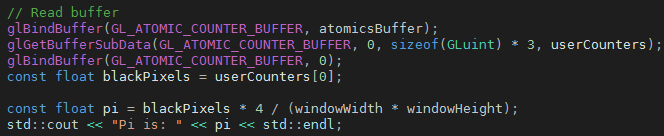
Specifically for the GPU you can use every point since that would be easier than picking random points. So you have a window of known width, and tell the GPU "if x-coord * x-coord + y-coord * y-coord < 1 then the point falls inside the quarter-circle" this is where you increment your atomics counter that you passed to the GPU, this is one of the few things you can get back from the GPU other than the colour sent to the screen.
Once the counter is returned you multiply it by 4 and divide by the area (width of window squared) to get Pi. This is because the ratio of the areas is given by: area of circle / area of square, Pi * R * R / 2 * R * 2 * R, the R's cancel, so you get Pi / 4.
Yes, there is an if-statement in a shader program. It is the one place that it is acceptable.
The fastest time to calculate Pi on the CPU was 280.27ms this was a 64-bit app configured for release mode. On the GPU it took 2ms.